-
[NLP Project] 일상 속 대화 적절하게 요약하기프로그래밍/Project 2025. 1. 8. 18:43

Dialogue Summarization (일상 대회 요약) 경진대회 개요
회의나 토의, 사소한 일상 대회 등 일상생활에서 대화는 수시로 이루어지고 있다.
또한 그 수많은 대화들을 대화가 끝난 후에 기억에 의존해서 요약하게 되면 잘못된 내용이나 누락되는 내용이 생기기 마련이다.
회의나 토의 등과 같이 중요한 대화의 경우에는 녹음을 해둘 수도 있지만, 장시간 이어진 대화를 전부 다시 듣기에는 비효율적이기 때문에 요약이 필요하다.
이런 불편함을 개선하기 위해서 일상 대화를 바탕으로 요약문을 생성하는 모델을 구축하고자 한다.
당장 나 또한 대화가 끝난 이후에 정리하려다가 기억하지 못하고 누락되는 것들이 많다.
대학 강의를 들을 때에도 장시간 연속으로 강의를 듣다 보면 전체적인 내용이 필요할 때도 있지만 요약이 필요하다고 느낄 때도 많아서 여러 방면으로 활용하기 좋은 기술인 것 같다.
데이터 구성

우선 학습 데이터는 데이터 번호(fname), 대화문(dialogue), 요약문(summary)으로 구성되어 있고, 테스트 데이터는 데이터 번호(fname)와 대화문(dialogue)만 있는 형태로 되어 있다.
데이터 증강

우선 주어진 학습 데이터의 주제를 뽑아내서 Solar나 ChatGPT 등 LLM을 활용해서 데이터를 증강하는 것을 시도했다.
기존에 주어진 데이터가 12457건으로 약간 부족한 것 같았고 다른 프로젝트들을 진행할 때에도 데이터를 어느 정도 증강하고 진행하는 것이 성능 개선에 도움이 됐던 경험이 있었고, 프로젝트 중간에 진행했던 멘토링에서도 데이터 증강을 시도해 보는 것이 좋은 방법이라는 답을 들어서 진행했다.
모델
모델은 우선 텍스트 요약에 특화된 모델인 koBART를 사용했다.
이외에 추가로 T5나 Gemma도 다른 팀원들이 시도했지만 시간이 너무 오래 걸리거나, 서버의 메모리 부족으로 셧다운 되는 증상이 반복되어 제대로 진행하지는 못했다.
모델 레이어 프리징

- 프리징 없이 모든 레이어 학습 => 과적합 위험 존재
- 인코더는 프리징하고 디코더만 학습 => 사전학습된 인코더 특성 보존
- 인코더와 디코더 모두 하위 50% 레이어 프리징 => 하위 레이어의 특성 유지
위의 방식으로 모델 레이어 프리징을 실험했다.

3가지 방식으로 학습한 모델들을 소프트 보팅 방식으로 앙상블했다.
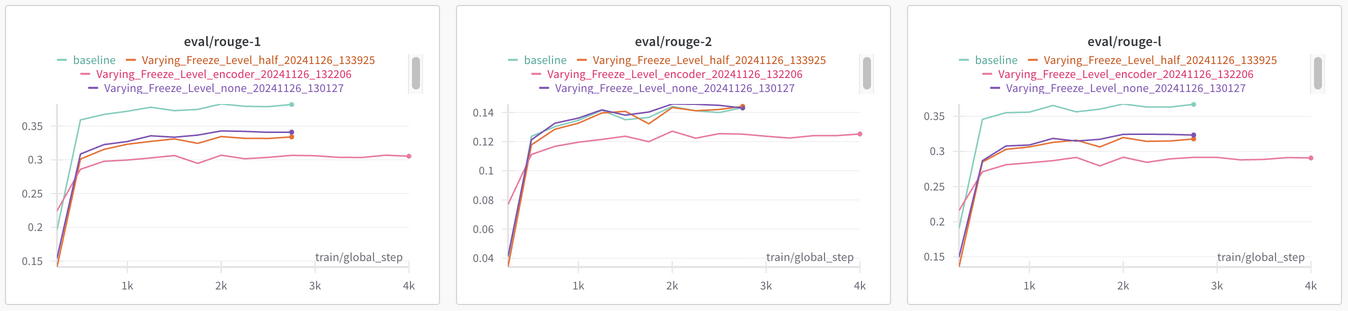
각 모델들을 학습할 때 WanDB를 활용해서 ROUGE 값을 기록해서 기존 베이스라인 코드와 비교를 해봤다.
각 모델들이 베이스라인 코드의 모델보다 성능이 좋지 않았는데, 각 모델들이 제대로 요약하는 영역이 다를 수 있다고 판단해 앙상블까지 진행했다.

baseline ROUGE-1/ROUGE-2/ROUGE-L/final_result 
앙상블까지 진행한 최종 결과는 베이스라인보다 약간 낮게 나왔다.
이후에 모델 학습 중에 측정되는 ROUGE 값을 기준으로 모델의 프리징 범위가 달라지도록 해보기도 했는데 오히려 더 안 좋은 모습을 보였다.
결과

결과적으로 베이스라인 코드의 성능에서 크게 개선시키지 못했다.
아무래도 우리 팀이 잡은 실험 방향이 이번 프로젝트에서 요구하는 것과는 맞지 않는 방향들이 있었거나 미흡한 부분이 있었던 것 같다.
느낀 점
내가 진행했던 모델 레이어 프리징도 디코더는 아예 제외하고 진행한다거나 하는 추가로 실험해 볼 수 있는 것들이 많았는데, 초반에 모델 선정 부분에 있어서 헤매게 되면서 실험할 시간이 부족해 진행하지 못한 것들이 많았다.
대회 발표를 진행했을 때도 강사님께서 진행한 실험의 방향성은 괜찮았고, 내가 아쉽다고 느낀 부분을 콕 집어주신 걸 생각하면 더 아쉬웠다.
이번 대회를 진행하면서 대화문을 정확하게 요약하는 것이 생각보다 어려웠고, 주어진 데이터도 마스킹 작업이 제대로 되어 있지 않은 그런 부분들이 나중에 확인되면서 데이터를 육안으로 한번 확인하는 과정을 진행하는 것이 중요하게 작용할 수 있다는 걸 알 수 있었다.
실제로 상위권을 차지한 팀 중에서 데이터를 제대로 수정하는 것만으로 모델의 성능이 오른 경우도 있었다.
가벼운 모델로 요약을 잘할 수 있다면 일상생활에서도 충분히 활용할 수 있을 것 같아서 나중에 한번 개인 프로젝트로 진행해 봐도 좋지 않을까 싶다.
'프로그래밍 > Project' 카테고리의 다른 글
[기업 프로젝트] RAG 시스템: 모델 선택부터 배포까지 (0) 2025.02.17 [RecSys Project] 고객 맞춤 상품 추천 시스템 만들기 (0) 2025.01.11 [CV Project] 육안으로 분간하기도 힘든 문서 딥러닝으로 분류하기 (0) 2024.11.12 ML Ops 음악 추천 시스템 프로젝트 회고 (4) 2024.10.16 아파트 실거래가 예측 경진대회 회고 (0) 2024.09.23